Full-Text Search for Zotero PDFs
TLDR
The final product looks like this:
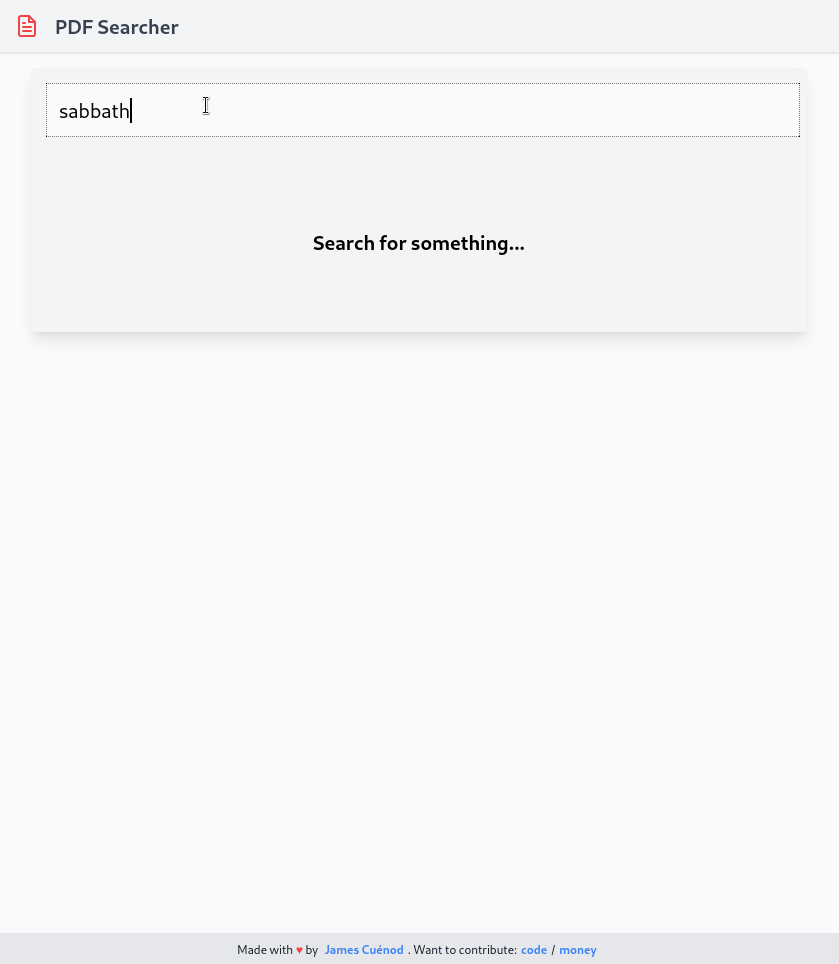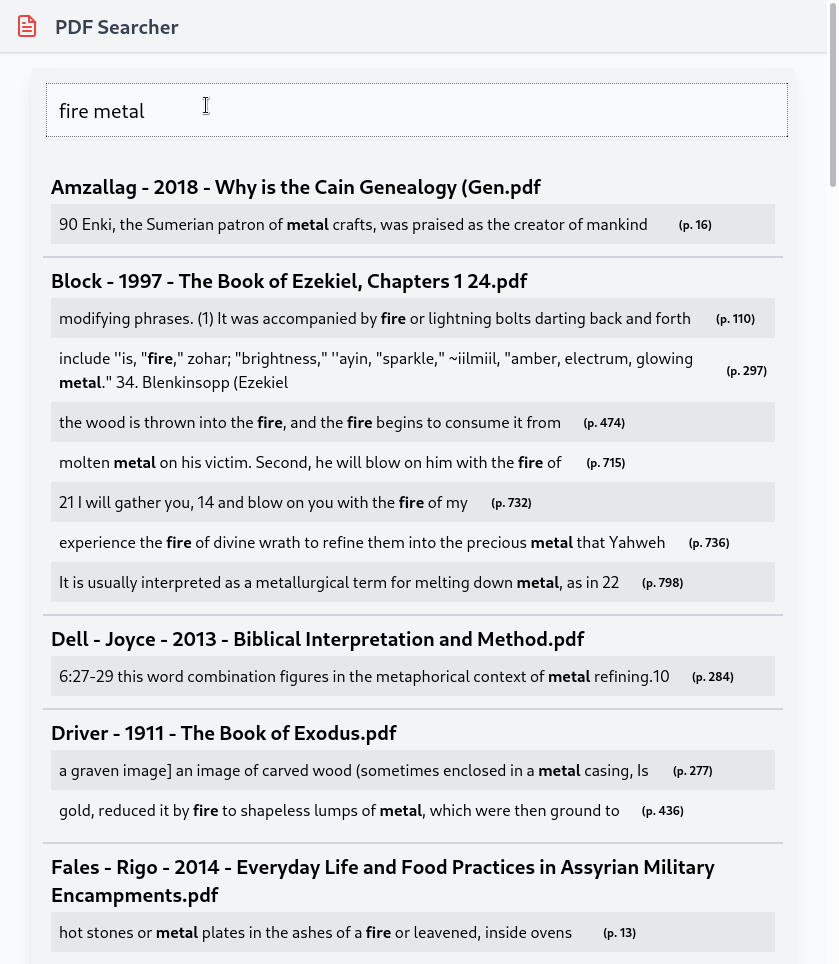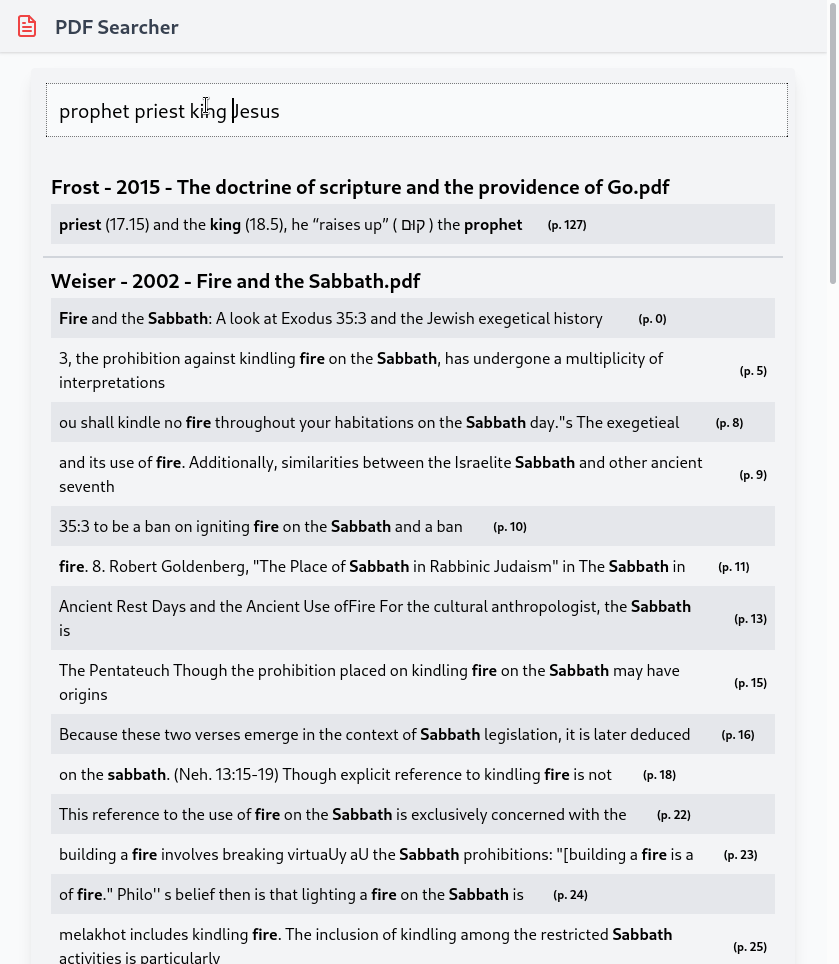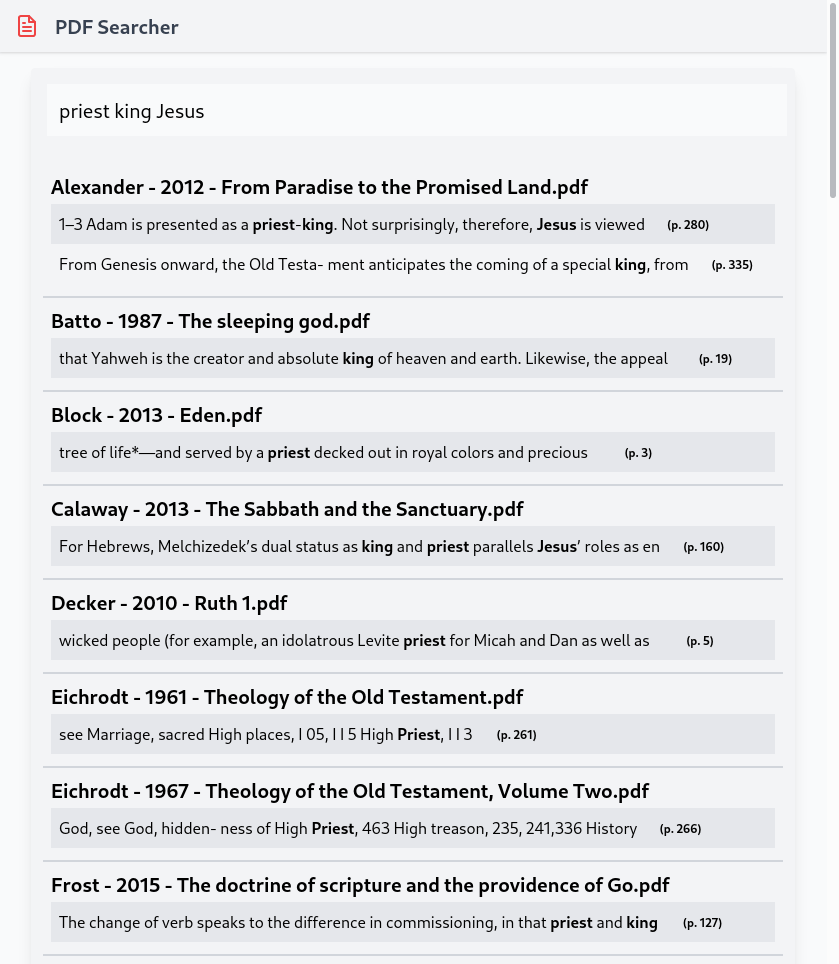
The Problem
I have a bunch (thousands) of PDFs in my Zotero storage. I want to find places where any of those PDFs mention particular content. But I want searches that are more sophisticated than just ’exact phrase’ searches.
Full Text Search with Sqlite
SQLite is basically one of the most amazing technologies in existence. It’s a database in a file and it is great! One of the cool features that it has is call FTS, full-text search.
To create a table that uses Full-Text search, you create a virtual table:
CREATE VIRTUAL TABLE EXISTS pdf_content USING fts5(
id,
page,
content
)
A virtual table is a normal table with special functions; in this case, full-text search (hence USING fts5).
With this kind of table, you can run queries like:
SELECT
page,
snippet(pdf_content, 2, '<b>', '</b>', '', 15) as extract
FROM
pdf_content
WHERE
content MATCH 'NEAR("search" "terms")'
The snippet function is a bit opaque but its signature is:
pdf_content: Name of the table2: Index of the column (zero based)<b>: String to inject before a matching token</b>: String to inject after a matching token'': String to inject at beginning and end of string if there is not a matching token there15: Number of tokens to return (i.e. length of snippet)
Grabbing Text out of PDFs
The next problem is how to get all the text into the database. I have all my zotero PDFs in ~/Zotero/storage/ but how can I pull text out of them?
I decided to use node because I’m proficient and figured I could make it work fast (but there are CLI tools that I considered using). The solution I got working the quickest was to use the legacy build of pdfjs-dist:
const pdfjsLib = require("./node_modules/pdfjs-dist/legacy/build/pdf")
async function getPdfText(path) {
let doc = await pdfjsLib.getDocument(path).promise
const pageText = []
for (let i = 0; i < doc.numPages; i++) {
const page = await doc.getPage(i + 1)
const content = await page.getTextContent()
let output = content.items.map(item => {
return item.str
}).join(" ")
pageText.push(output)
}
return pageText.map(page => page.trim())
}
module.exports = { getPdfText }
As you can see, a combination of doc.getPage() and page.getTextContent() gets the content of each page. The getPdfText function returns a (promise) array of content. Each page is an element in the array.
The combination of an FTS table in SQLite and this PDF-text-extractor can be found at https://github.com/jcuenod/pdfindex-create-index/. This repo also builds a metadata table that stores the name, size, and path of the PDF (so that I can, in theory, tell if I’ve already indexed it and just skip over it).
Querying
The query above works great on this table. With the metadata table that I generated in my indexing, the query that I use is:
SELECT
metadata.rowid as rowid,
name,
page,
snippet(pages, 2, '<b>', '</b>', '', 15) as extract
FROM
pages,
metadata
WHERE
content MATCH 'NEAR("search" "terms")'
AND
pages.id = metadata.rowid) fts
This query works like a charm but I very quickly found that some PDFs were full of matches and that made the results pretty noisy. So I wanted to GROUP BY PDF. Something like this:
SELECT
name,
group_concat(page, ', ') as pages,
group_concat(extract, '___SEPARATOR___') as extracts
FROM (
SELECT
metadata.rowid as rowid,
name,
page,
snippet(pages, 2, '<b>', '</b>', '', 15) as extract
FROM
pages,
metadata
WHERE
content MATCH 'NEAR("search" "terms")'
AND
pages.id = metadata.rowid) fts
GROUP BY rowid
The inner query here is identical to the one above. All that I’m doing is trying to GROUP BY rowid (rowid is a hidden column that SQLite automatically adds as a PRIMARY KEY to your tables [with some exceptions]). Grouping by rowid means a PDF will never show up in the results more than once. This obviously suppresses the prominence of PDFs that have tons of matches but it also surfaces more interesting results because I probably already knew about the ones with tons of matches.
If I run the query above with only SELECT name FROM ... (and drop the group_concat lines from the SELECT), it works as expected. I can add in the group_concat for pages and the query continues working. Now it produces a comma separated list of matching page numbers. The last step is to get my snippet/extract back (which was working in the previous query). But when I run it with group_concat(extract ... I get:
Error: unable to use function snippet in the requested context
The same error results using a CTE instead of a subquery.
bang head against wall for a while … solution!
It turns out that SQLite does “subquery flattening”.
When a subquery occurs in the FROM clause of a SELECT, the simplest behavior is to evaluate the subquery into a transient table, then run the outer SELECT against the transient table. Such a plan can be suboptimal since the transient table will not have any indexes and the outer query (which is likely a join) will be forced to do a full table scan on the transient table.
To overcome this problem, SQLite attempts to flatten subqueries in the FROM clause of a SELECT. This involves inserting the FROM clause of the subquery into the FROM clause of the outer query and rewriting expressions in the outer query that refer to the result set of the subquery. For example:
SELECT t1.a, t2.b FROM t2, (SELECT x+y AS a FROM t1 WHERE z<100) WHERE a>5Would be rewritten using query flattening as:
SELECT t1.x+t1.y AS a, t2.b FROM t2, t1 WHERE z<100 AND a>5
So SQLite is optimizing my use of a CTE etc. into the same basic query and ripping the snippet function out of its nested context. The solution is annoyingly simple. Force the inner query to materialize results so that it can’t be flattened. This can be accomplished by adding:
LIMIT -1 OFFSET 0
The final working query is:
SELECT
name,
group_concat(page, ', ') as pages,
group_concat(extract, '___SEPARATOR___') as extracts
FROM (
SELECT
metadata.rowid as rowid,
name,
page,
snippet(pages, 2, '<b>', '</b>', '', 15) as extract
FROM
pages,
metadata
WHERE
content MATCH 'NEAR("search" "terms")'
AND
pages.id = metadata.rowid
LIMIT -1 OFFSET 0) fts
GROUP BY rowid
ORDER BY name
LIMIT 100;
Part of the frustration with this problem is that neither highlight nor snippet seem to be used with GROUP BY very often so googling did not produce many results and it took me a while to realize that I should expand my search to include the highlight function because it is doing something pretty similar to snippet (and I tested and realized it also didn’t work).
Finishing it Off
The final step is to make an interface that doesn’t require this cumbersome query to get a set of results and that doesn’t force me to visually grep the results in a terminal. Thus, sprinkle some express magic and you have a server that responds to /query?q=search terms (which is now here) and then sprinkle some react magic and you have a client that debounces requests and produces results on the fly (here). At this point, after pointing the server to our SQLite index and the client to our server, we are back at the TLDR…